
I wrote my last entry, Random Variables and Distributions, primarily to give us the background to discuss entropy (and in the process, a little bit about coding theory, a subfield of information theory). Information theory is critical to modern technology—communication, data compression, and much of cryptography—and increasingly, to fields that study information in a more abstract sense, like neuroscience, gambling, and genomics, for example. When I introduced information theory in my last post, I said that information theorists study quantities with strong similarity to our understanding of what information should do. We are going to start with the grandaddy of them all: entropy. I’ll talk about its definition, then we’ll dive into three different examples, then finish with a very brief discussion of coding theory.
You’ve probably heard about entropy in physics and chemistry—the Second Law of Thermodynamics. Entropy in information theory has a similar form—thermodynamics far pre-dates information theory—but the two aren’t quite the same (although you can derive the second law from information theory principles). Information entropy requires less machinery than its thermodynamic ancestor to properly define—all you need is a random variable and its distribution.
Entropy Definition
The entropy of a random variable X with probability density function p(x) is given by


- Note that we can choose any log base, and this changes the units of entropy: if it’s
, it’s bits, if it’s
it’s nats, and so on. But usually we care about bits.
- p(x), the probability density function for a random variable X, is a function that takes in possible realizations x of X and outputs the probability of that realization. For example, for a fair die roll, I could plug “2” into my probability density function p(x), and it would output
.
- E(X) denotes the expected or mean value of a random variable X. The expected value measures the average of a bunch of realizations of our random variable X. For example, if I roll the die many times, I should expect my average roll value to be
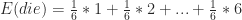
Now in the definition, it looks a little messier—E(p(X)) is the expected value of p(X), which is a function of a random variable. But worry not, it’s still a random variable itself. But why would we make it more complicated? The expected value has a lot of handy properties, so probabilists like to find ways to represent functions on random variables in terms of expected value. When entropy is expressed as an expected value, we have access to all sorts of powerful tools.
Entropy is often described as a measure of disorder, and while not necessarily wrong, it doesn’t really paint a clear picture. The entropy measures the average minimum number of yes-no questions (if in bits) we have to ask to fully characterize a realization of a random variable. That probably doesn’t really clear it up—it certainly didn’t make sense to me at first. Let’s explore some examples to see what this really means.
Example 1: Entropy of a coin flip
Imagine I flip a fair coin, then quickly hide the result. How many yes-no questions do you need to ask to be fully confident that you can ascertain the outcome of this experiment? You only need to ask 1—namely, “Is it heads?”. With that one question, you know everything you need to know about my experiment. A quick calculation shows that:

Indeed, on average, we only need 1 question to describe an outcome of the experiment.
Example 2: Entropies of fair and unfair die rolls
Now imagine I’m rolling a fair die, and again hiding the result. But even you, with your remarkable result-guessing skills, can’t reliably determine the result with just one yes-no question. How many do you need on average then?
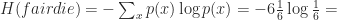
which makes sense—we would need 2 questions for 4 possibilities, and 3 questions for 8 possibilities, so 6 should be somewhere in between. But what about a nonuniform distribution, say 

So this nonuniform distribution has less entropy than the uniform over the same support set. Thus, if we design our questions cleverly and exploit this structure, we need fewer questions on average to reliably ascertain the outcome of an experiment.
It’s like when Sherlock Holmes has a lead—Sherlock should spend his first question checking the prime suspects (1 and 2), and then move on. Without a lead, Holmes is forced to ask more questions on average:
- Is it less than 4?
- If so, is it 1?
- If not, is it 2?
The first question cuts the space of possible numbers in half. The second cuts off a third of the space 

But with a lead, he can ask less questions on average:
- Is it less than 3?
- If so, is it 1?
1 and 2 are such frequent offenders that choosing this decision strategy requires less questions most of the time and thus a lower average over many cases, even though identifying 3, 4, 5, and 6 will necessarily require more questions. Sherlock’s efficiency with the common cases outweighs the inefficiency for uncommon cases.
As a sidenote, this result is not specific to this distribution. In fact, any distribution necessarily has less entropy than the uniform distribution over the same set. Reliable leads will always make your searches better on average.
Example 3: A revolutionary channel
But why do we care about how many questions it takes to characterize a realization of a random variable? As it turns out, this answers a dual problem: what is the average length of a codeword (a string of letters used to represent some data) in the most efficient lossless code for some set of data?
Suppose I want to send some data to my good pal Paul Revere—for example, a string of digits 1, 2, 3, 4, 5, and 6. Naturally, our only available communication channel is a lantern, and we agree that raised = 1, and lowered = 0. Naively, we first design our code like so:
1=000 2=001 3=011 4=100 5=101 6=110
We test it out on this string of data:
154345154245564 (15 digits)
⇓
000 100 011 010 011 100 000 100 011 001 011 100 100 101 011 (45 bits: 3 bits/digit)
When I talk to Paul the next day, my sore arm helped me realize something—we could do better than that. So we re-design our code and send a new message:
1=0 2=1 3=10 4=11 5=100 6=101
452345551345645 (15 digits)
⇓
11 100 1 10 11 100 100 100 0 10 11 100 101 11 100 (35 bits: 2.33 bits/digit)
That’s much better. 12 fewer bits, that’ll make my life much easier. But Paul isn’t satisfied—he thinks we can do even better. But how? We can’t count any better—this is binary, and we’ve exhausted our smallest numbers. Paul notes that there is some structure in my messages—the numbers “4” and “5” appear more than the others, so to make an even better code, we could assign our smaller codewords to these more common numbers. So we implement Paul’s idea:
1=11 2=100 3=10 4=0 5=1 6=101
345144655244451 (15 digits)
⇓
10 0 1 11 0 0 101 1 1 100 0 0 0 1 11 (22 bits: 1.47 bits/digit)
Paul exploited a feature of the data I was sending to make a more efficient code—a dramatically more efficient code. But at any particular moment, Paul didn’t know what I was about to send. He only knew that I tend to send “4”s and “5”s frequently. So—how can we mathematically compute the limit of how efficiently we can represent our data?
We model the situation by describing the nth digit as a random variable supported on the alphabet 
Coding theory
Coding theory studies the properties of various codes, which are simply representations of some data. This last example represents a basic concept from coding theory—if we model our source data as a random variable, a judicious choice of code can make for more efficient messages, and the most efficient code possible sends data whose average length is the entropy of that random variable . This is the core goal of compression.
But the most efficient code isn’t necessarily the “best”. Perhaps the issue with our channel is not space, but noise—here, we may optimize our coding scheme to combat noise. This is exactly what error-correcting codes are designed to do.
Coding theory is an area of fascinating research today, and it’s finding all sorts of cool applications all across science. Actually, I was first introduced to information theory by a coding theorist collaborator and good friend of mine, David Schwartz. He’s currently investigating coding schemes that may be implemented by biological neural networks. We’re both interested in the fundamental means by which the brain holds, transfers, and computes information. This has implications for both our theoretical understanding of the brain and the future of artificial neurally-inspired learning. If you have some time, I recommend checking out some of these related labs: LIPS (David’s lab), the Sharpee lab, the Fiete lab, and the LeCun-Fergus lab.
*Food: Rosemary and thyme sous vide steak with eggs over sourdough, caramelized onions, garlic, and an arugula salad with dried cherries, mustard seed and white cheddar. I did the beer cooler method, and it worked marvelously. I love cheap, easy methods.

Leave a comment